数据截至 2026-06-10 | 本文由 Fable 5 模型和丁亦锟共同撰写
“Scaling 撞墙了。”
“AI 泡沫马上就破。”
“AGI 还有 18 个月。”
2026 年的 AI 圈,大概是科技史上分歧最严重的现场:一边是模型能力每 4 个月翻一倍的曲线,一边是 81% 的企业高管说 AI 没带来有意义的利润。
那么真实情况是怎样的呢?
我们把 2023–2026 年能找到的硬数据全拉了一遍:39 个基准缝合成的能力指数、METR 的任务时长、固定能力的推理价格、三种统计方式下的采用率、8 项随机对照试验、五大云厂的 capex(资本开支,主要是买芯片、建数据中心的钱)、头部实验室的收入——43 个公开数据源,6 张图。
先划重点:
- 模型层不仅没减速,2024 年上半年还踩了一脚油门。三个互相独立的数据源指向同一个拐点:能力增速 ×1.85,任务时长翻倍周期从约 8 个月缩到约 114 天,固定能力价格年降幅从 50 倍升到 200 倍。
- 应用层”慢”是个错觉,慢的只有利润。使用和收入都是指数:Claude Code 12 个月做到年化 80 亿美元,token 用量 25 个月涨了 330 倍。但 81% 的企业仍说 AI 没带来有意义的利润影响。
- 钱的缺口还有 9 倍,但性质变了:分母(收入)18 个月涨了 5–7 倍。
- 真正的图景不是”模型快、应用慢”,而是三条曲线的相位差:能力是指数曲线,采用是 S 曲线早段,利润是 J 曲线谷底。
下面逐层拆。
01|尺子不够用了:基准从发布到”报废”,只要11个月
评价 AI 快慢,第一反应是看跑分。
但 2023 年之后,跑分图越来越难画了——不是因为模型涨不动,是因为尺子坏得太快。
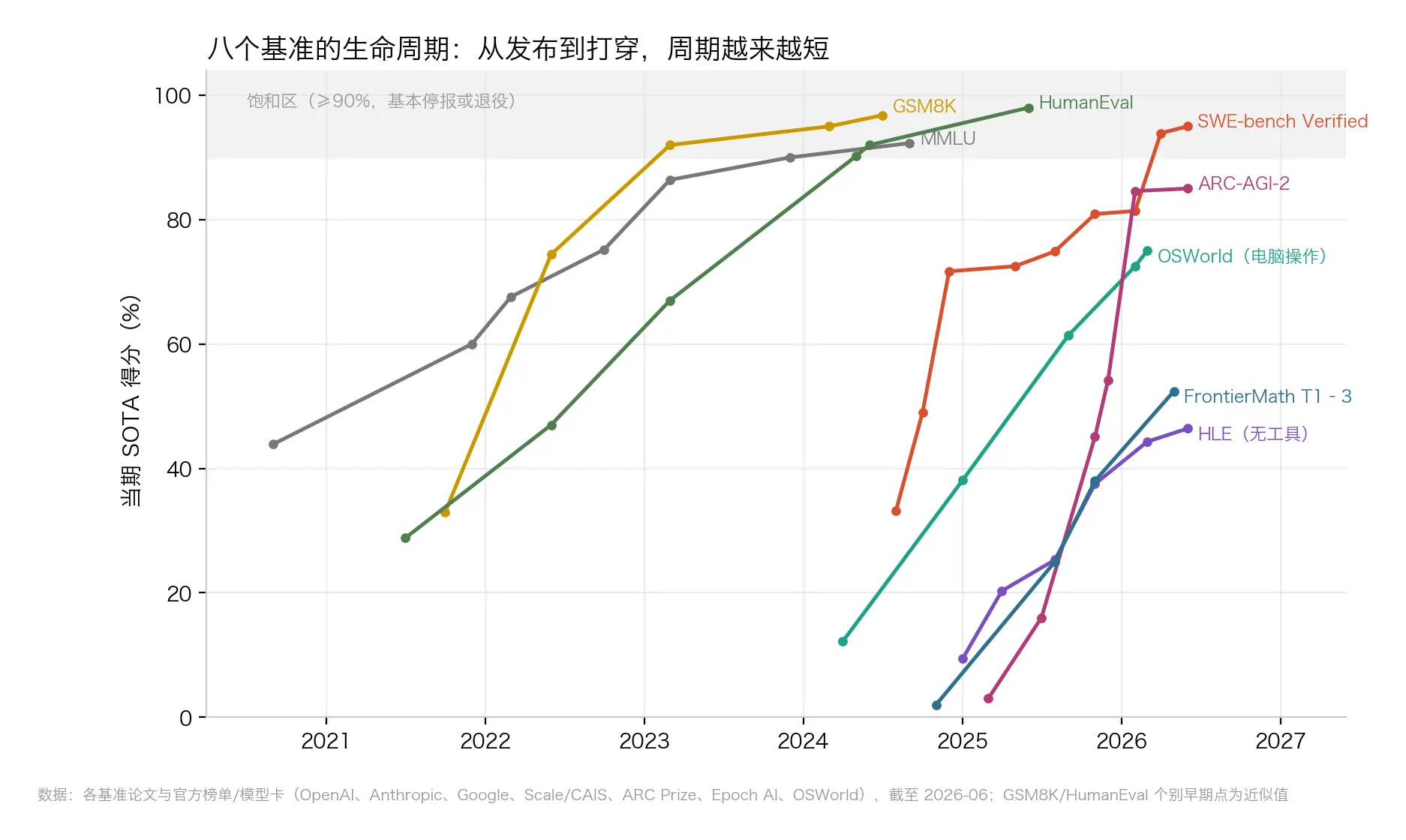
△ 图1:八个代表性基准的生命周期,灰色阴影为 ≥90% 的饱和区。各基准分数不可横向比较,看的是各自”发布→打穿”的形状
把 2020 年以来的代表性基准放进同一张图,规律一目了然:
- MMLU(2020 年发布):GPT-3 起步 43.9%,被推过 90% 用了约 39 个月;
- GSM8K(2021 年):29 个月被打到 95%,随后因数据污染退役——题目泄进了训练数据,相当于考生提前背过答案;
- SWE-bench Verified(2024 年 8 月):起步 33.2%,15 个月越过 80%(Claude Opus 4.5),20 个月后 93.9%,最新一代模型约 95%;
- ARC-AGI-2(2025 年 3 月):号称”专为难住大模型设计”,发布时所有推理系统得分 ≤3%。11 个月后,84.6%(Gemini 3 Deep Think)。
发布→打穿,从 3 年,缩到 15 个月,再缩到 11 个月。
现在全行业没被打穿的尺子只剩两把:HLE(Humanity’s Last Exam,“人类最后的考试”,各学科压箱底难题的合集,最高分 46.4%)和 FrontierMath(职业数学家出的研究级数学题,T1–3 口径 52.4%)。更尴尬的是,后者刚被 Epoch 审计出约 1/3 的题目本身有缺陷——
出题的速度,已经赶不上做题的速度了。
顺带说一句 agent:OSWorld(让模型操作真实电脑的基准)从 12.2% 涨到 75%,只用了 23 个月,已超过人类基线的 72.4%。Agent 不是比聊天能力慢,只是同一条曲线晚两年起跑。
02|把39个基准缝成一把尺子:拐点,2024年4月8日
单个基准会饱和、会污染、会退役,怎么办?
学界的办法:用统计模型把几十个基准对齐到同一把尺子上,原理类似把不同年份、不同难度的高考卷换算成可比的标准分。Epoch AI 的能力指数(ECI)就这样缝了 149 个模型、39 个基准。
把历代最强模型的分数连成一条”前沿线”,分两段各拟合一条直线,看斜率在哪一天变了。结果是这样:
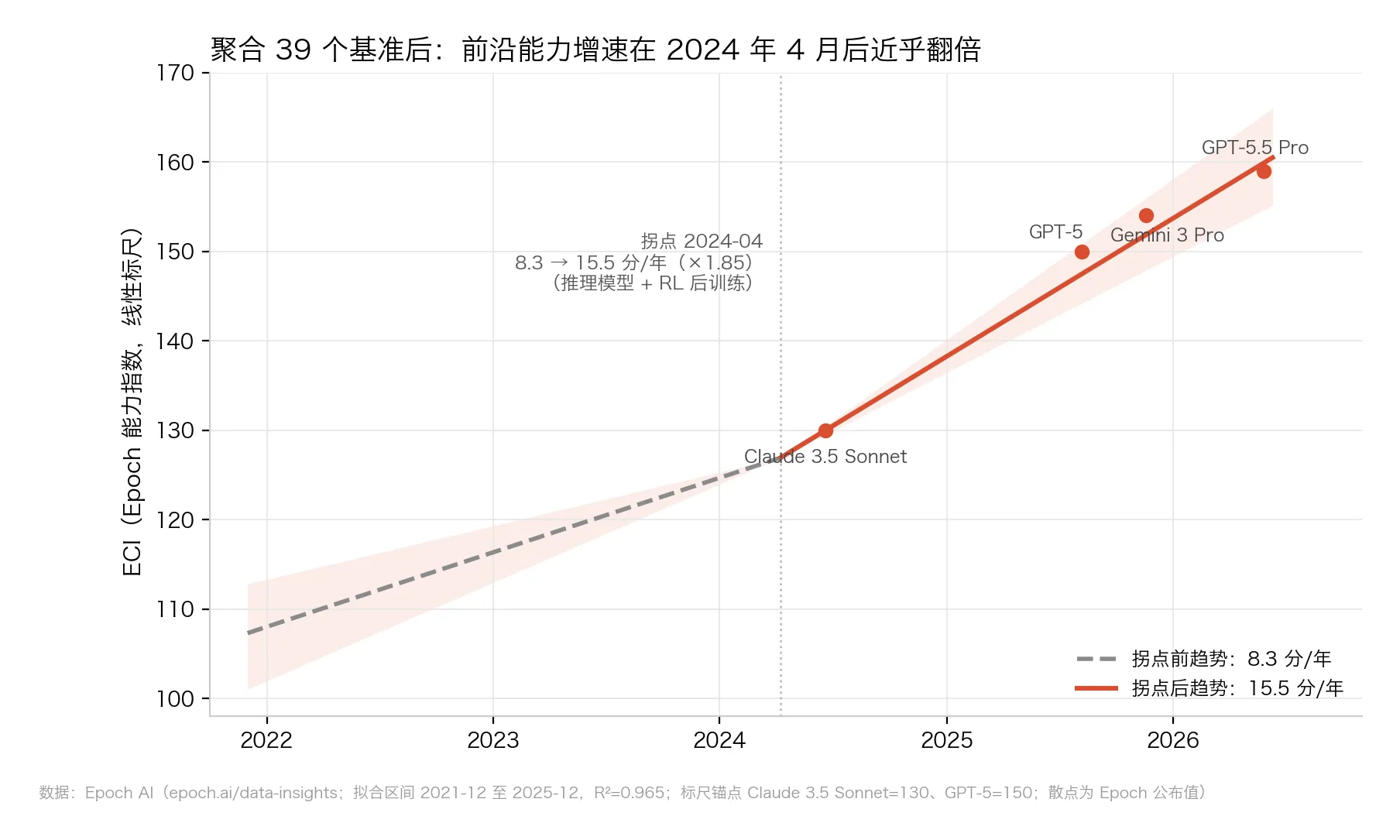
△ 图2:Epoch 能力指数(ECI)前沿趋势,虚线为拐点前斜率的外推
拐点:2024 年 4 月 8 日。斜率从 8.3 分/年跳到 15.5 分/年,×1.85(R²=0.965——这个拟合指标满分是 1,0.965 意味着折线几乎完美贴合数据)。
这是什么时间点?行业把重心转向大规模强化学习后训练的窗口——五个月后,o1 那一代”先想再答”的推理模型正式登场。
而且拐点后的趋势线,到今天还压得住:GPT-5 150 分、Gemini 3 Pro 154 分、GPT-5.5 Pro 159 分——基本就贴在 15.5 分/年的延长线上。
没有放缓的迹象。
03|换把不会饱和的尺子:从3秒到17小时
跑分有上限,时间没有。
METR(伯克利的一家非营利评测机构)的”时间地平线”指标换了个聪明的量纲:模型能以 50% 成功率完成的任务,换成人类专家来做,需要多久。
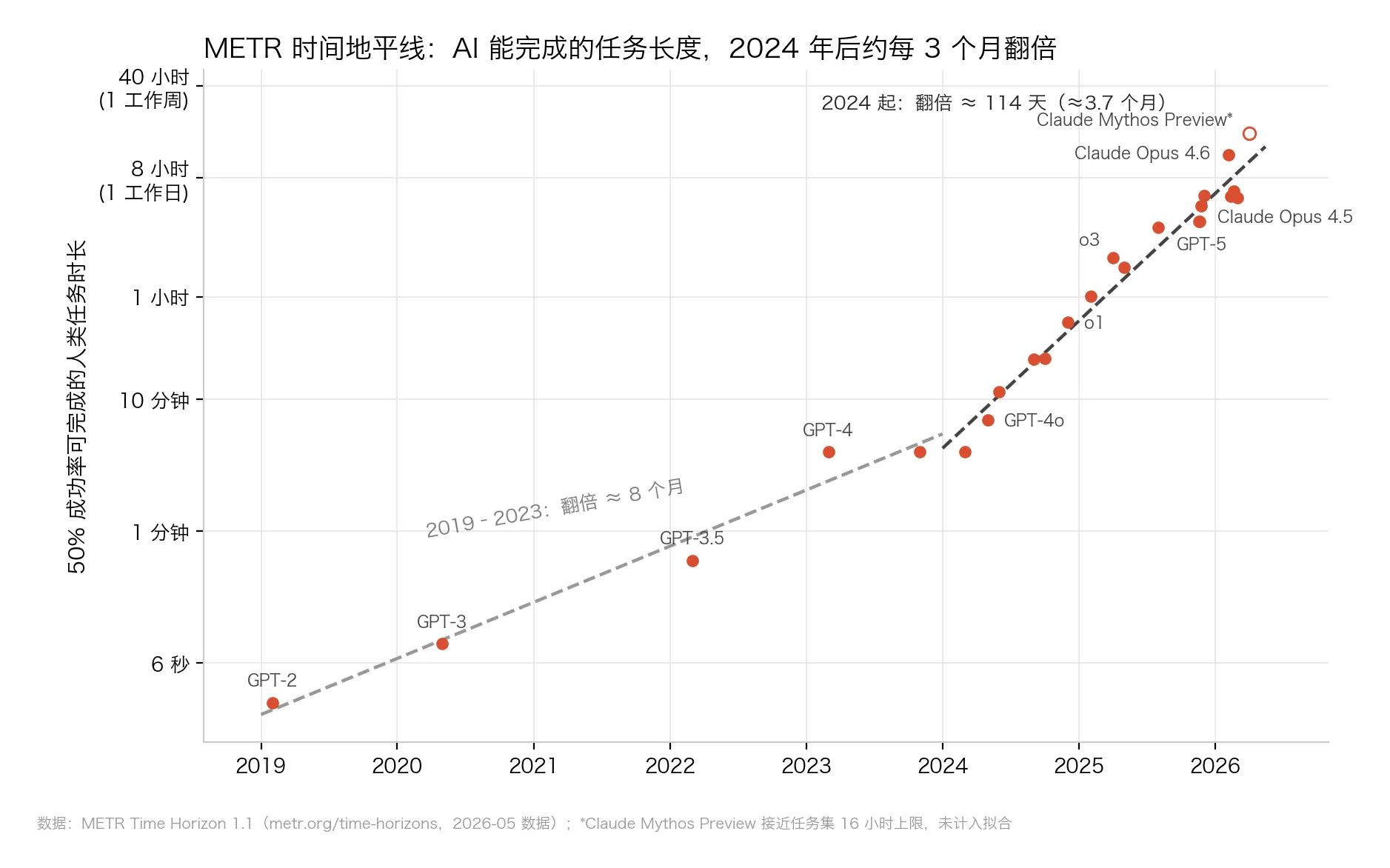
△ 图3:METR 50% 时间地平线(对数轴)。最新点已顶到任务集 16 小时上限,未计入拟合
这条线横贯 5 个数量级:
- 2019 年,GPT-2:约 3 秒;
- 2026 年 4 月,Claude Mythos Preview:约 17 小时。
翻倍周期:2019–2023 约 8 个月;2024 年起,约 114 天(本文用其公开数据重绘的拟合;METR 官方 TH1.1 口径为 89 天)。2026 年初,Claude Opus 4.6 的地平线约 12 小时——一个工作日级别的任务。
交互式 agent 也是同一个形状:τ²-bench(让 agent 在多轮对话里帮用户查订单、改机票的客服基准),2024 年 GPT-4o 不足 50%,GPT-5.2 已经 98.7%。
但注意一个细节:50% 成功率是条宽松的及格线,要求 80% 成功率,地平线大约短一个数量级。“基准上像超人、工作流里像实习生”,数学根源就在这——第 07 节还会回来。
04|智能在通缩,旗舰在涨价
效率,是模型层叙事里最被低估的一半。
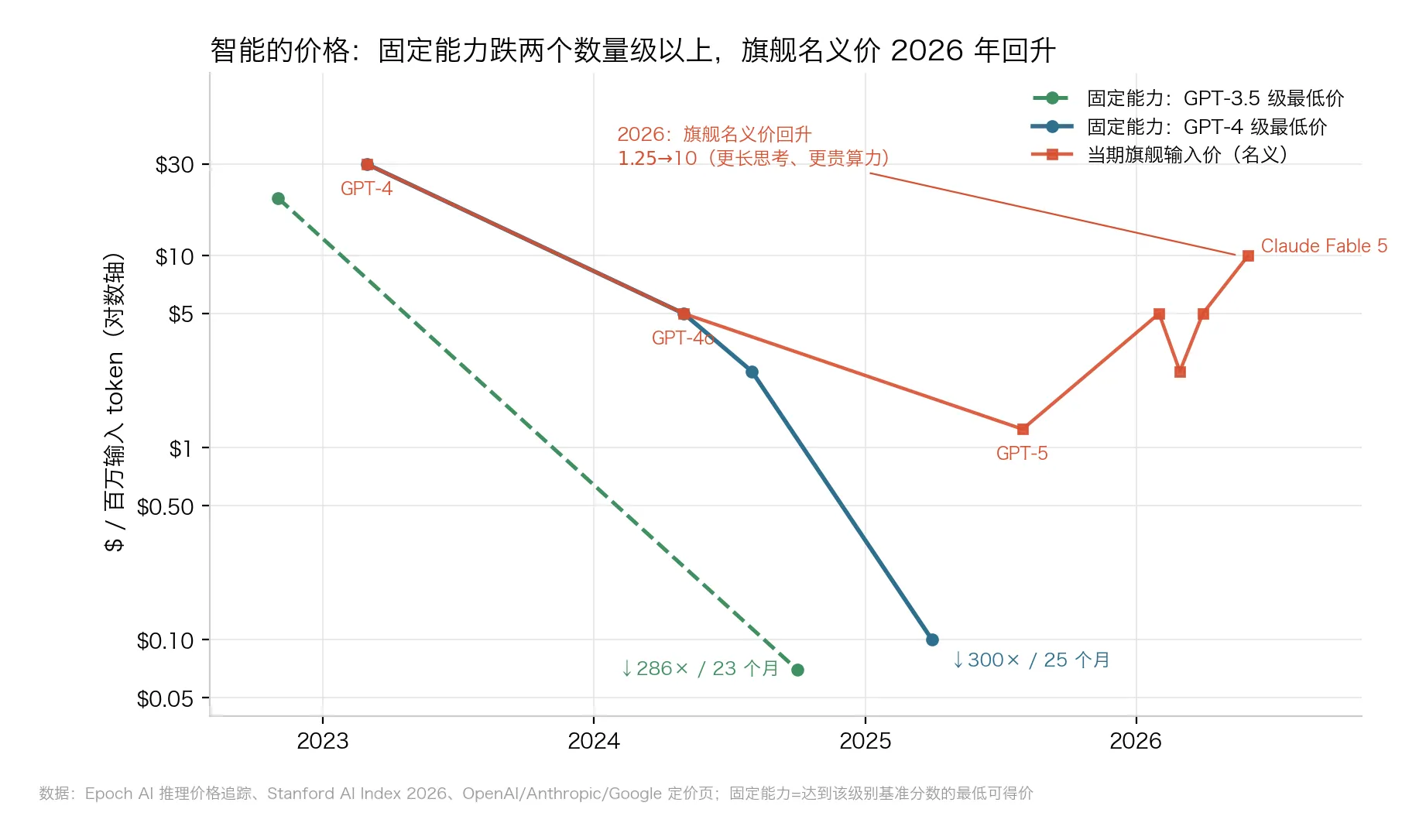
△ 图4:智能的价格双轨——固定能力在崩塌,旗舰名义价在回升
固定能力的价格在崩塌:
- GPT-4 级:$30 → $0.10/百万 token(token 是模型计费的文本单位,一百万 token 大约是 75 万个英文词),两年降了 300 倍;
- GPT-3.5 级:$20 → $0.07,约 280 倍;
- Epoch 测算:固定能力价格年降幅中位数约 50 倍,2024 年之后的窗口升到约 200 倍/年。
但另一条线反着走:旗舰名义价格 2026 年掉头向上——GPT-5 发布价 $1.25,GPT-5.5 涨到 $5,Claude Fable 5 直接 $10。
“智能通缩”只对固定能力成立,对前沿能力不成立。买两年前的智能,价格是地板价;买此刻最强的智能,厂商正在重新定价。
到这里,模型层三条独立证据链全齐了:ECI 拐点 2024-04、METR 翻倍周期 2024 年起减半、降价斜率 2024 年起翻两番。“2024 年上半年开始第二段加速”,是当前 AI 数据里最稳的结论。
供给侧也对得上:前沿训练算力约 5×/年,算法效率约 3×/年——两项相乘,有效算力一年涨约 10 倍。
05|应用层:用的人指数涨,赚到钱的只有1%
模型这么猛,企业赚到钱了吗?
这是全文最拧巴、也最有信息量的一层。
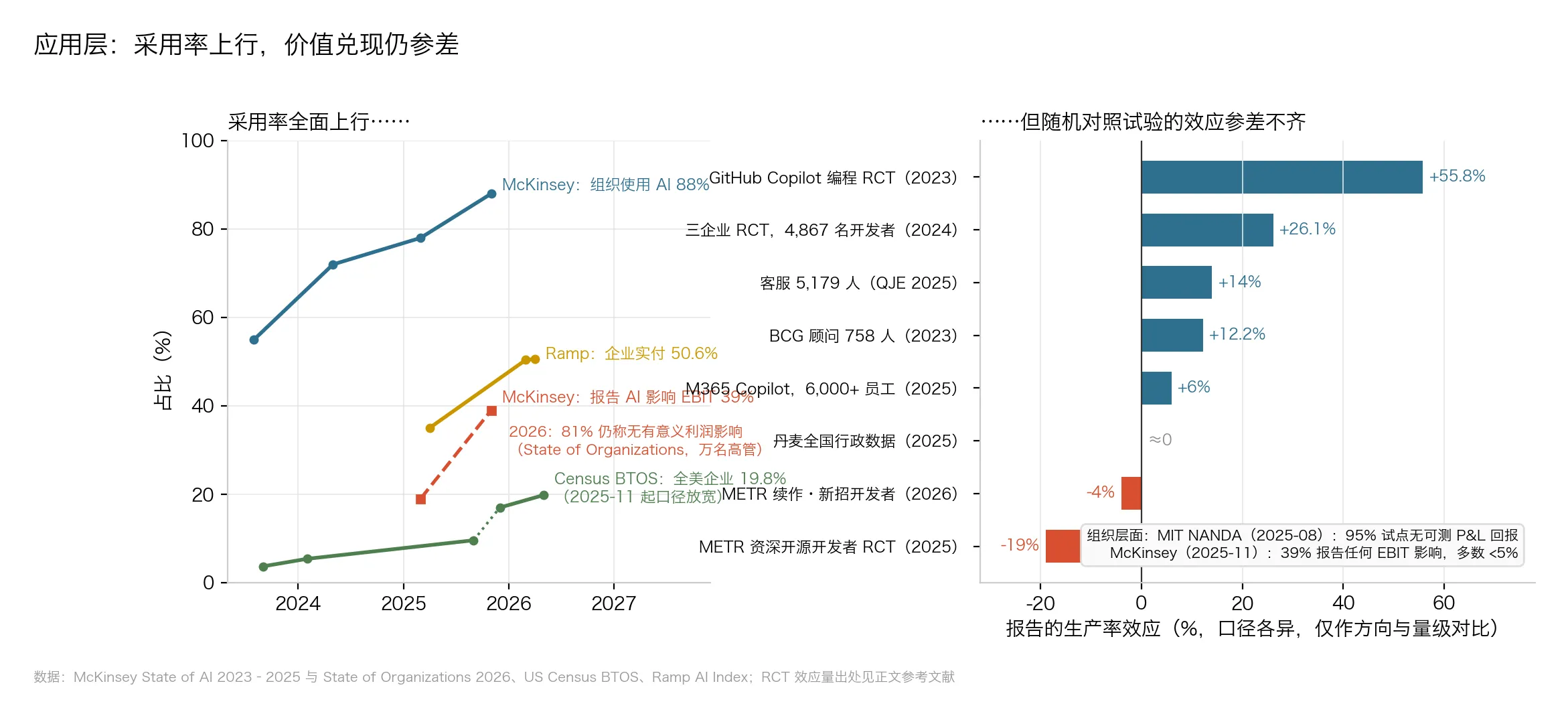
△ 图6:左为三种统计方式下的采用率与利润影响,右为 8 项因果研究测出的生产率效应,从高到低排成一列
第一个问题:多少企业在用 AI?
这个问题没有唯一答案——取决于你问谁、怎么算:
- 问大企业高管”你们组织用没用 AI”,McKinsey 的调查:88% 说在用;
- 不听口头的,看账单。Ramp 是一家帮企业管信用卡和报销的公司,能直接看到几万家客户把钱付给了谁——按它的数据,50.6% 的美国企业在真金白银地为 AI 产品付钱,一年前还是 35%;
- 把全美所有企业都算上(包括理发店、修车行),美国人口普查局的官方调查:在用的只有 19.8%。
三个数字差出 4 倍多,但没人说谎:大公司先动,嘴上说用的多过真掏钱的,小店大多还没碰。关键是方向——三条线全在涨。
第二个问题:用了 AI 的人,真的干活更快了吗?
注意,“在用”不等于”有用”。要回答这个问题得做实验,标准做法叫随机对照试验(RCT),和测新药一模一样:把人随机分成两组,一组发 AI、一组不发,干同样的活,最后掐表。两组的速度差,就是 AI 的真实贡献。
图 6 右侧把 8 项最严肃的研究按结果从大到小排成一列,结果横跨整个光谱——从快 56%,到反而慢 19%:
- +55.8%:招两组程序员写同一个小程序,用 GitHub Copilot 的那组快了一半还多。任务标准、目标明确——AI 的主场;
- +26%:微软、埃森哲和一家财富 100 强公司的近 5,000 名程序员,在日常工作里测了几个月,用 AI 的组多完成约 26% 的任务;
- +14%:5,179 名客服配上 AI 助手后,每小时多解决 14% 的问题。新手提升最大,老手几乎不变(发表在经济学顶刊 QJE);
- +12.2%:BCG(波士顿咨询)的顾问做分析任务,快 12.2%。但研究者故意埋了几道”看起来 AI 能做、其实会做错”的题——这些题上,用 AI 的顾问反而错得更多;
- 零:上面都是几周到几个月的实验,丹麦经济学家直接翻了两年的全国账本:2.5 万名员工的官方工资、工时记录。结论是 AI 普及两年,收入和工时没有任何统计上可见的变化;
- −19%:8 项里唯一的负数。
最后这个 −19%,值得单独讲。
METR(就是第 03 节量”时间地平线”的那家评测机构)找来 16 位资深开源开发者,在他们自己维护了多年的代码库里做 246 个真实任务,每个任务随机决定”可以用 AI”或”不准用”。
结果:允许用 AI 的任务,平均慢了 19%。时间花在哪了?写提示词、等生成、审查 AI 的代码、修 AI 的错——在一个你熟到闭着眼都能改的代码库里,AI 更像一个需要手把手带的实习生。
更扎心的是体感:实验结束后让开发者自己估计,他们普遍觉得 AI 让自己快了 20%。秒表和体感,差了 39 个百分点。2026 年的后续实验,结果仍然没有翻正。
组织层面更冷:
- MIT NANDA 报告:95% 的企业 genAI 试点,在利润表上看不到可测量的回报(方法论有争议,但量级被广泛引用);
- McKinsey:只有 39% 的组织报告 AI 对 EBIT 产生过任何影响——EBIT 即息税前利润,可以粗暴理解为”主营业务到底赚没赚钱”。换句话说,61% 的组织连”有一点影响”都说不出口;
- 2026 年初的万人高管调查:81% 说没有有意义的利润影响,自评 AI 应用”成熟”的只有 1%。
看到这你可能想说:果然,应用层拉胯。
且慢。同一时期,还有另一组硬数据,形状完全不同:
- Claude Code:正式发布后 12 个月,做到年化收入 $8B(年化 = 按最近月收入 ×12 折算,下同);
- Cursor:三年做到 $2B;Devin:一年涨 13 倍,到 $4.92 亿;
- ChatGPT:9 亿周活,5,000 万付费订阅;
- Google 全口径 token 量:9.7 万亿/月 → 3.2 千万亿/月,25 个月 330 倍;
- Anthropic 经济指数:企业 API 流量里,77% 已经是”全自动”用法——模型独立跑完整个任务,而不是人和 AI 一来一回地协作。
使用是指数,付费是指数,唯独利润证据是平的。
慢的不是应用,是组织变革和会计确认。 Stanford AI Index 估算,美国用户每年从 AI 产品中”白赚”约 $172B 的消费者剩余(愿意付的价钱,减去实际付的价钱)——比全行业收入还高。大量价值真实存在,只是没落进 GDP 和利润表的统计口径。
06|钱:9倍缺口,和同一个月里方向相反的两个信号
资本的判断很直白:梭哈。
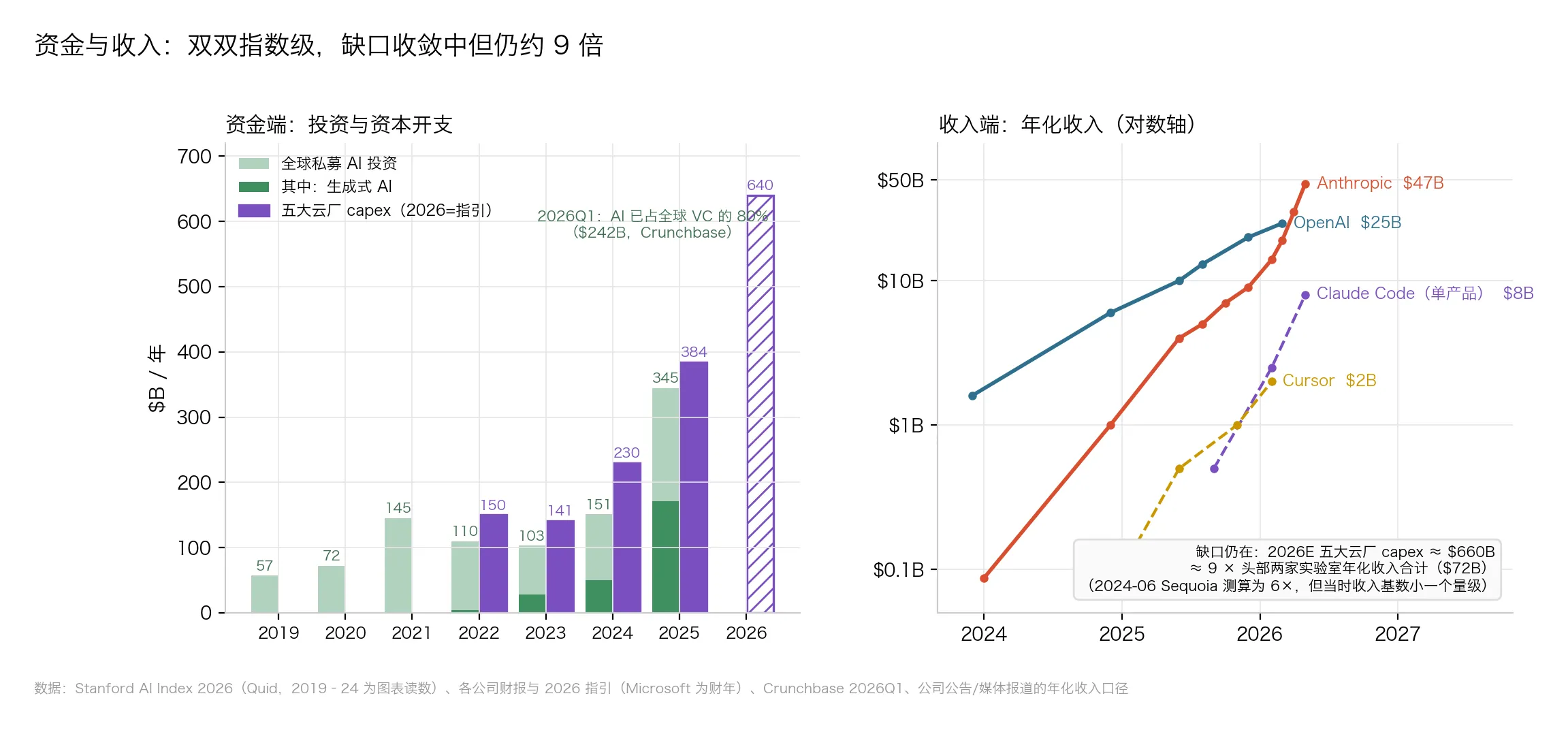
△ 图5:左为投资与 capex(柱),右为头部公司年化收入(对数轴),右下角标注 9× 缺口
- 2025 年全球私募 AI 投资 $344.7B(+127%),其中 genAI $170.9B;
- 2026 年 Q1,AI 拿走全球 VC 的 80%($242B);
- 五大云厂 capex:2023 年 $141B → 2025 年 $384B → 2026 指引 $610–690B。
收入端在指数追赶:OpenAI 年化 $25B+,Anthropic 年化 $47B,企业 genAI 支出(Menlo 口径)三年从 $2.3B 涨到 $37B。
但拿 2026E capex(约 $660B)除以头部两家实验室收入合计(约 $72B)——还是 9 倍。
2024 年 6 月,红杉资本发出著名的”$600B 之问”——AI 行业一年要去哪找 6,000 亿美元收入,才配得上买卡的钱?当时这个倍数是 6。倍数没好转,但分母(收入)18 个月涨了 5–7 倍,缺口的性质已经完全不同。
最微妙的是 2026 年 5–6 月,同一个行业给出两个方向相反的信号:
- Anthropic 预告首个盈利季度,并秘密递交 S-1(美股上市前的招股文件);
- 同期,OpenAI 把 $1.4T 的算力承诺下修到 2030 年前约 $600B。
Bain 的测算挂在头顶:到 2030 年,需要 $2T/年的收入才能支撑算力扩张,目前缺口 $800B。
资金层既不证实”泡沫破裂”,也不证实”需求无限”——它只是把第 05 节的剪刀差,用杠杆放大了一遍。
07|不是谁在撒谎,是四件事同时为真
能力指数涨、利润趴着不动,怎么可能同时成立?
四个机制,每个都有数据,互不矛盾:
1. 锯齿状边界:AI 的能力地图不是圆的,是锯齿状的。
人类的能力是连片的——会做微积分的人,必然会算加减法。AI 不是:它能拿下奥数题,转头却数不对一个单词里有几个字母;能写出复杂算法,却在一次简单的重命名里把代码改坏。强项和弱项犬牙交错,像锯齿。
BCG 实验里那个反差就是这么来的:任务落在 AI 的强项上,顾问快 12.2%;落在”看起来像强项、其实是弱项”的地方,用 AI 反而错得更多——而边界具体在哪,事先很难知道。
跑分测的是最高的那几颗齿尖;真实工作流要串起十几个环节,任何一环掉进齿缝,整条链就断。跑分由 AI 最强处决定,可用性由它最弱处决定。
2. 可靠性折价:及格线一提高,AI 能干的活大幅缩水。
METR 那个”12 小时”,按的是 50% 成功率——做两次成一次就算过。把及格线提到 80%(做五次成四次),AI 能胜任的任务马上从 12 小时级缩到 1–2 小时级。而企业要敢让 AI 真正进生产流程、不派人盯着,及格线往往得画到 99%。
听起来很致命?关键事实是:这个折扣不随时间变大。18 个月前,按 80% 及格线算,AI 只能干”几分钟”的活;现在是 1–2 小时——爬升速度和 50% 那条线一样快,只是晚跑了一程。
像同一条高速上的两辆车,时速相同,一辆落后几公里。落后的那辆不是不动,只是还没开到你家门口。
3. 组织吸收,历史上就是最慢的环节。
电这么划算的东西,工厂用了约 30 年才真正省出钱——因为光把蒸汽机换成电机没用,老厂房整个围着一根中央传动轴布局,必须推倒重建、给每台机器配上自己的电机,电的好处才兑现。IT 时代也一样,经济学家索洛 1987 年吐槽:“计算机无处不在,唯独不在生产率统计里。”
为什么总是这样?企业引入新技术,前几年是净投入:买工具、培训员工、重组流程、交学费——利润不升反降;改造完成后,利润才反超原点。把利润按时间画出来:先下探,再爬升,最后超过起点——形状正是字母 J。
所以 81% 没利润 + 1% 成熟,不是”AI 没用”的证据,而是整个行业正卡在 J 字那一竖的谷底。
4. 统计滞后:很多价值是真的,只是账本看不见。
最大的一块叫消费者剩余:你愿意为一样东西付的钱,减去实际付的钱。你可能觉得 ChatGPT 一个月值 300 块,但你用的是免费版——这 300 块的价值真实发生了,GDP 里记到的却是 0。Stanford 估算,仅美国,这类”白赚”的价值一年约 $172B,比全行业收入还大。
另外两笔账同理:AI 省下的时间多半被拿去干别的活,而不是变成裁员降本,所以财报上看不见;高管问卷问的是”已确认的利润影响”,从用上到敢在财报里认账,天然滞后 12–24 个月。
把四条放回数据,2023–2026 的一句话总结:
模型层在 2024 年初进入第二段加速(能力翻倍约每 3–4 个月、固定能力价格年降百倍),应用层的使用与收入以同样的指数形状跟跑、只落后一个相位,利润作为最滞后的指标还停在 J 曲线谷底——这不是技术放缓,这是通用技术扩散的标准时序。
08|未来12个月,盯这8个数
不想追 43 个数据源?盯住下面 8 个数就够了。
两个胜负手:
① “AI 对利润有影响”的企业占比(McKinsey 调查,现在 39%)。J 曲线有没有开始抬头,就看它:突破 50%,说明利润开始兑现,2024–2026 这波天量投入就算押对了;要是一年后还停在 40% 以下,“还在 J 曲线谷底”的辩护就开始失效——同样的坏数据,“产能过剩”会变成更站得住脚的解释。
② 算力开支 ÷ 头部实验室收入(现在约 9 倍)。比值开始收敛,说明收入在追上来;继续发散,泡沫警报才真正响起。
三个看模型还快不快:
③ METR 的 80% 及格线地平线(现在 1–2 小时)——第 07 节那个”可靠性折扣”在不在缩小;
④ HLE 和 FrontierMath 的分数(现在 46.4% / 39.6%)——最后两把没打穿的尺子还能撑多久;
⑤ 旗舰模型标价(Fable 5:$10/百万 token)——再涨,“智能越来越便宜”的故事就要改写。
三个看应用和钱:
⑥ 人口普查局的全企业采用率(现在 19.8%)——理发店和修车行们什么时候跟上;
⑦ 下一代 agent 基准的起步分——如果新尺子一发布就被打出高分,说明出题真的跟不上做题了;
⑧ Anthropic 盈利季兑现 + IPO 定价(预告 2026Q2)——全行业第一份”AI 能赚钱”的审计级证据。
One More Thing
本文所有判断都建立在一个隐含假设上:这些尺子本身还能撑住。
但现实是——HLE 只剩一半空间;FrontierMath 被审计出 1/3 的题有缺陷;METR 最新的数据点(约 17 小时)已经顶到任务集 16 小时的上限,统计上只能记作”≥16 小时”,连拟合都进不去。
人类出题的速度,第一次系统性地跑输了 AI 做题的速度。
这件事,有人提前一年就说破了。
2025 年 4 月,姚顺雨——SWE-bench 和 τ-bench 的作者之一(本文引用的两把尺子都出自他手),时任 OpenAI 研究员、如今的腾讯首席 AI 科学家——写了一篇广为流传的《The Second Half》,核心判断两条:
AI 的下半场——从现在开始——重心将从”解决问题”转向”定义问题”。在这个新时代,评测变得比训练更重要。
AI 下棋赢了世界冠军,考试超过了大多数人类……但世界没有太大变化,至少从经济和 GDP 看是这样。我把它称为效用问题(the utility problem),这是 AI 最重要的问题。
为什么跑分和现实脱节?他给的根源:评测的基本设定和真实世界不一样——评测假设 AI 独立跑完全程,现实里人要全程参与;评测一道题做完就清零,现实任务一个接一个、互相纠缠。
你大概也看出来了:本文第 05 节的全部拧巴——基准超人、RCT 翻车、利润趴窝——几乎就是这两段话的脚注。
下次再聊 AI 发展的速度,可能得先发明新的尺子。而能出题的人,正在变成这个行业最稀缺的资源。
说明与限制:收入均为公司披露的年化 run-rate,非审计收入更非利润;Census BTOS 2025-11 起问卷口径放宽,前后不可严格比较(图中已虚线断开);MIT NANDA 的 95% 存在方法论争议;METR 翻倍周期本文重绘为 114 天、官方 TH1.1 口径为 89 天;本文仅覆盖公开英文数据源,对中国及开源生态系统性低估。
主要数据源:Stanford HAI AI Index 2026 · Epoch AI(ECI / 推理价格 / FrontierMath)· METR(arXiv:2503.14499, Time Horizon 1.1)· OpenAI / Anthropic / Google 官方披露 · McKinsey State of AI · US Census BTOS · Ramp AI Index · QJE 140(2) · arXiv:2302.06590 · SSRN 4945566 · HBS WP 24-013 · NBER w33777/w34255 · MIT NANDA · Sequoia “AI’s $600B Question” · Shunyu Yao “The Second Half”(2025-04) · Crunchbase · Menlo Ventures · Bain Global Technology Report